KFServing
Beta
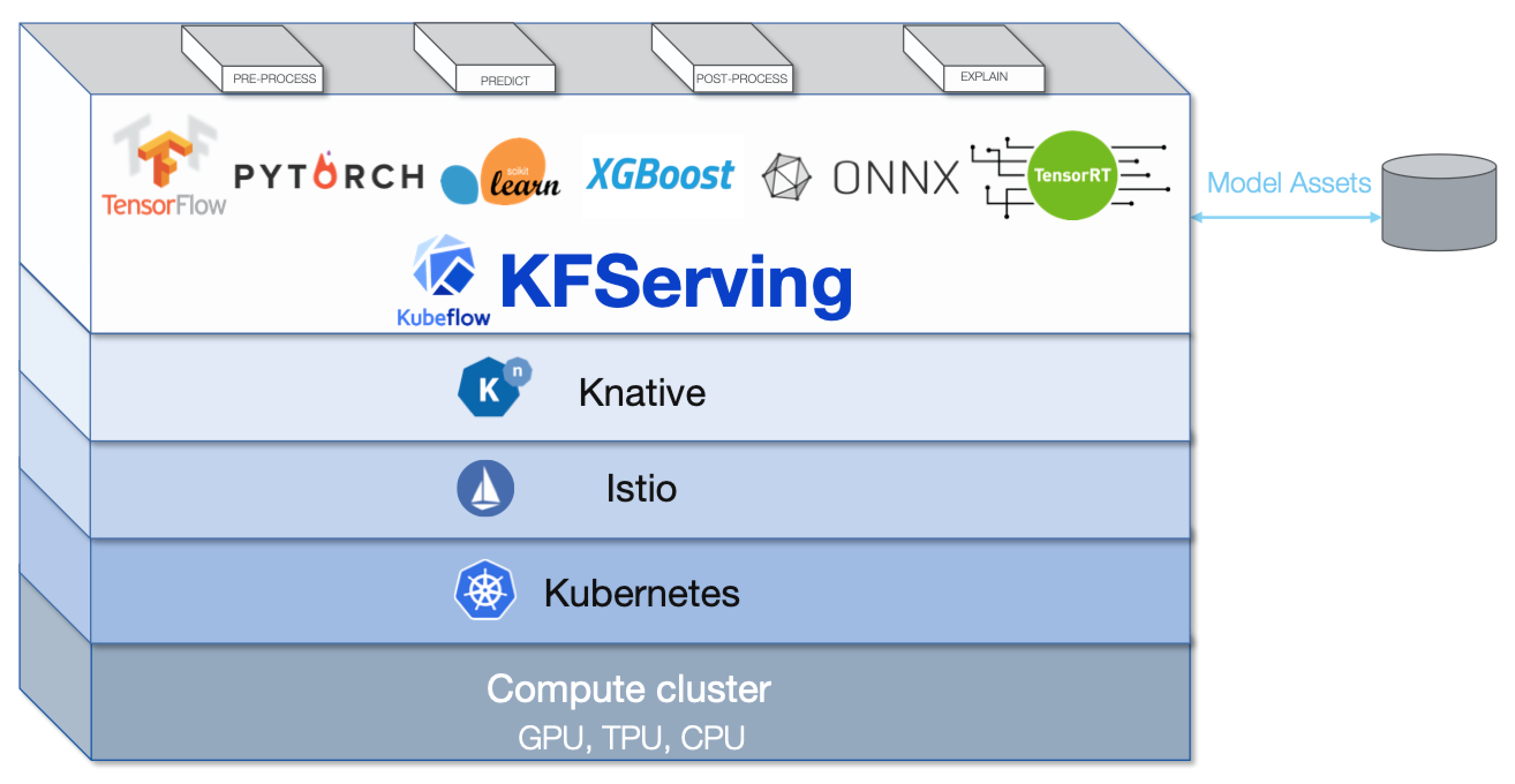
This Kubeflow component has beta status. See the Kubeflow versioning policies. The Kubeflow team is interested in your feedback about the usability of the feature.KFServing enables serverless inferencing on Kubernetes and provides performant, high abstraction interfaces for common machine learning (ML) frameworks like TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX to solve production model serving use cases.
You can use KFServing to do the following:
-
Provide a Kubernetes Custom Resource Definition for serving ML models on arbitrary frameworks.
-
Encapsulate the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU autoscaling, scale to zero, and canary rollouts to your ML deployments.
-
Enable a simple, pluggable, and complete story for your production ML inference server by providing prediction, pre-processing, post-processing and explainability out of the box.
Our strong community contributions help KFServing to grow. We have a Technical Steering Committee driven by Bloomberg, IBM Cloud, Seldon, Amazon Web Services (AWS) and NVIDIA. Browse the KFServing GitHub repo to give us feedback!
Install with Kubeflow
KFServing works with Kubeflow 1.3. Kustomize installation files are located in the manifests repo.
Check the examples running KFServing on Istio/Dex in the kubeflow/kfserving repository. For installation on major cloud providers with Kubeflow, follow their installation docs.
Kubeflow 1.3 includes KFServing v0.5.1 which promoted the core InferenceService API from v1alpha2 to v1beta1 stable and added v1alpha1 version of Multi-Model Serving. Additionally, LFAI Trusted AI Projects on AI Fairness, AI Explainability and Adversarial Robustness have been integrated in KFServing, and we have made KFServing available on OpenShift as well. To know more, please read the release blog and follow the release notes
Examples
Deploy models with out-of-the-box model servers
Deploy models with custom model servers
Deploy models on GPU
Autoscaling and Rollouts
Model explainability and outlier detection
Integrations
Model Storages
Sample notebooks
We frequently add examples to our GitHub repo.
Learn more
- Join our working group for meeting invitations and discussion.
- Read the docs.
- API docs.
- Debugging guide.
- Roadmap.
- KFServing 101 slides.
- Kubecon Introducing KFServing.
- Kubecon Advanced KFServing.
- Nvidia GTC Accelerate and Autoscale Deep Learning Inference on GPUs.
- Hands-on serving models using KFserving video and slides.
Standalone KFServing
Install Knative/Istio
Knative Serving (v0.17.4 +), Istio (v1.9+), and Cert Manager(v1.0.0+) should be available on your Kubernetes cluster. For installing KFServing prerequisites, refer to the README section.
KFServing installation
Once you meet the above prerequisites KFServing can be installed standalone.
Check the KFServing install directory for other available releases.
Monitoring
Use SDK
-
Install the SDK with PiPy.
pip install kfserving -
Follow the example(s) to use the KFServing SDK to create, patch, roll out, and delete a KFServing instance.
Contribute
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.